


Is Cloud Forensics just Log Analysis? The cloud sure does have a lot of logs. There are IAM logs, application logs, infrastructure logs, operating system logs…and everything in between.
Complicating the situation further, there are esoteric “inaccessible logs” that only the cloud providers have access to. Or the logs may be accessible, but the cloud provider hasn't bothered to document them. Florian Roth explained the situation brilliantly with this Tweet:

But logs aren’t everything when it comes to performing forensics in the cloud. There is still “full content” (not meta-data) available across Disk, Network and Memory in the cloud if you know how to access it. And in the case of many investigations, it’s impossible to identify the true root cause of an incident without this critical context.
The unfortunate reality, though, is that in many cases “cloud forensics” is performed by analyzing logs alone - mostly due to the amount of overhead involved in accessing, processing and analyzing higher-fidelity data sources. However, a faster and smarter way to gain access to network, disk and even memory evidence across cloud systems is possible.
Below I’ve outlined some ways of answering the question “Is Cloud Forensics just Log Analysis?” to help clarify the rapidly emerging field of cloud forensics.
Is this just a question of differing definitions?
We spoke to one our forensic experts at Cado and he suggested that if your definition of cloud forensics is “forensic of the cloud provider’s control plane”, then it is indeed true to say that Cloud Forensics = Log Analysis:
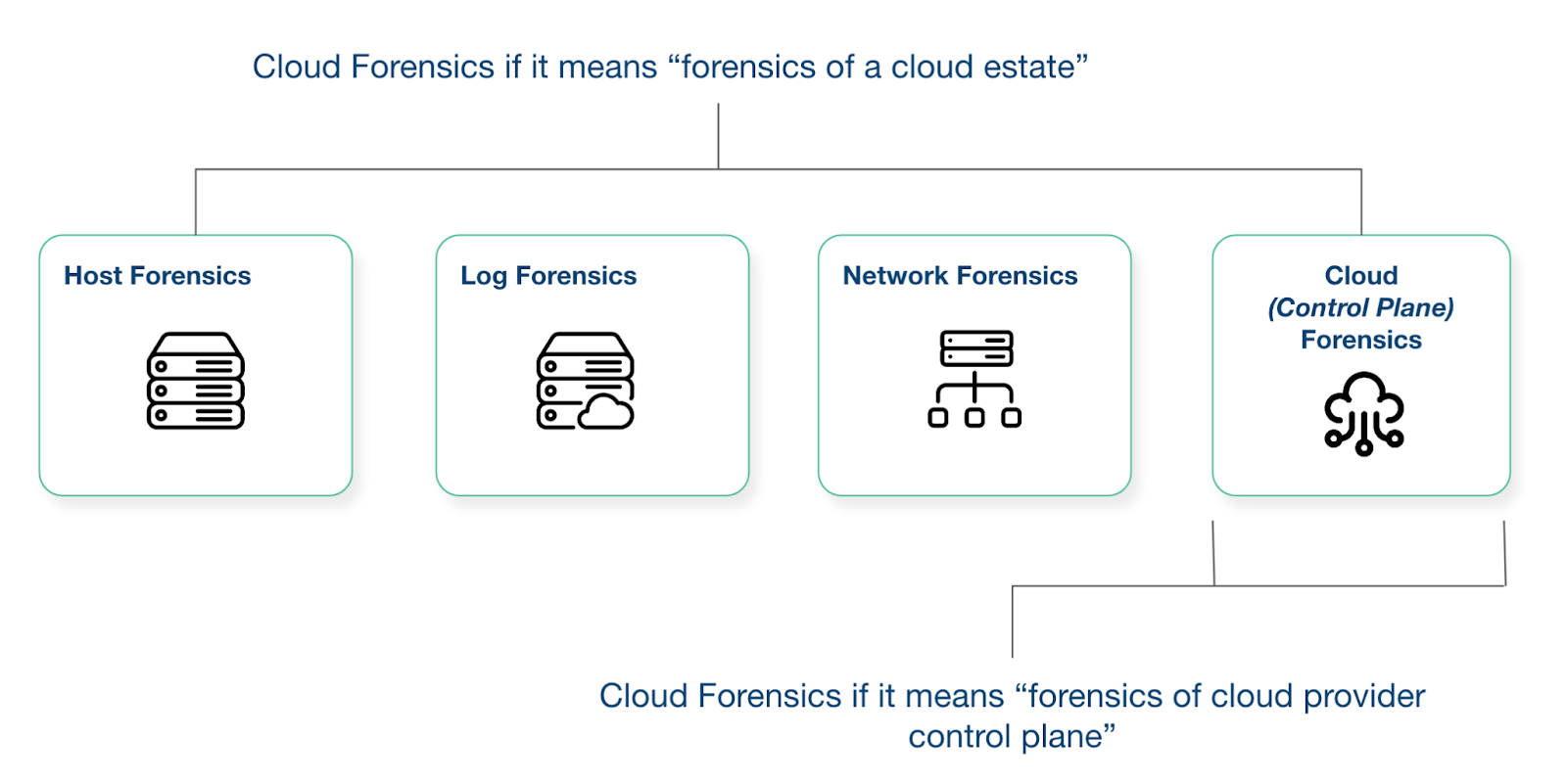
An Example:
Here is an example of a compromise in the cloud, a fairly complex example involving containers:
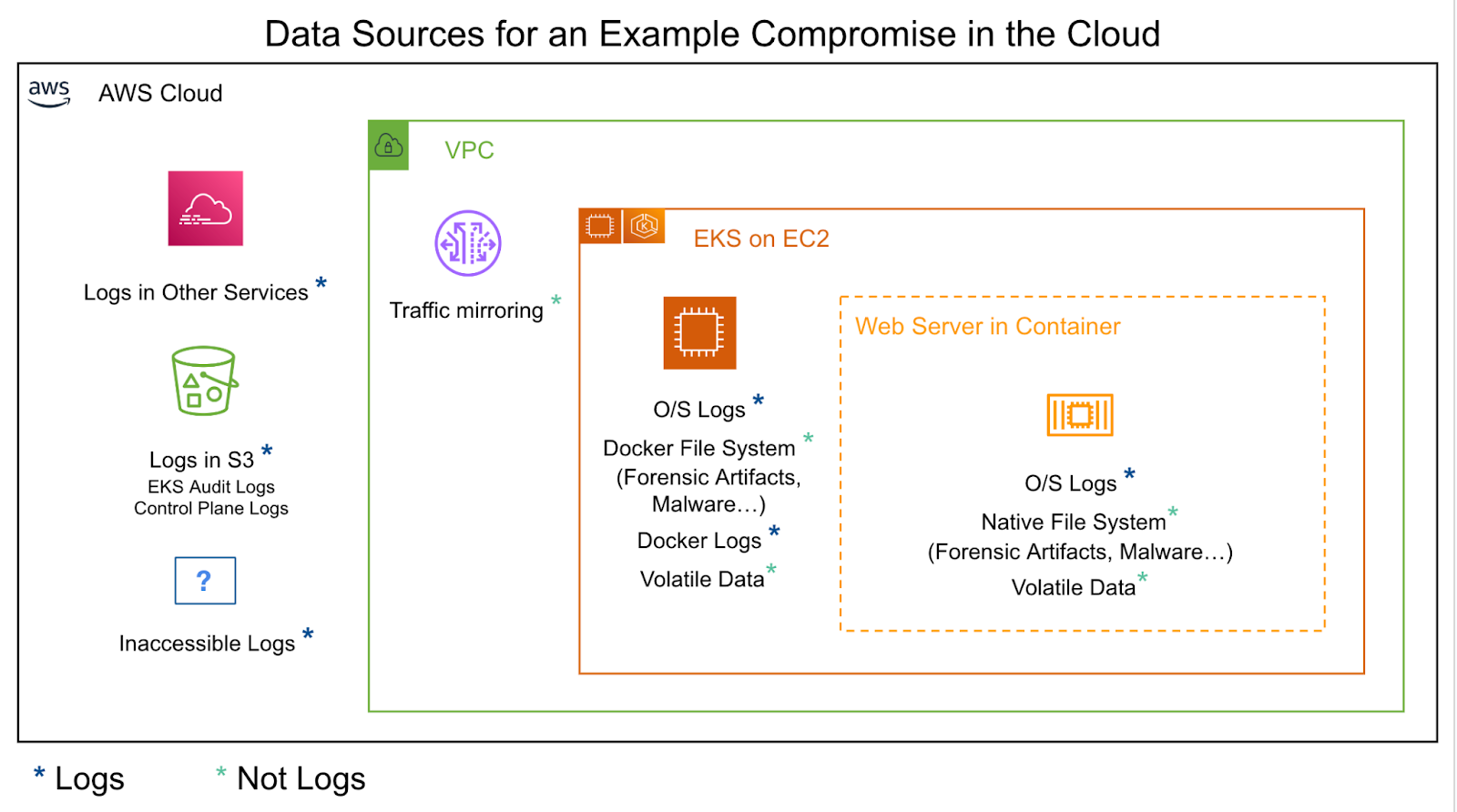
Cloud compromises are as varied as the infrastructure that underpins them. But this is a pretty typical example most people responding in the cloud will have seen many times before:
- Containers are hosted on a virtual machine or dedicated cloud provider infrastructure
- A docker container has an exposed and vulnerable service
- An attacker compromises the container, and performs *some evil* to gain access to credentials for the cloud environment
- The credentials are then abused to pivot and complete objectives. For example, stealing data from cloud storage or spinning up infrastructure to mine cryptocurrency.
Let’s step through the data you’ll need to properly investigate this incident:
- Files on the original container. For example this could contain malware or forensic artifacts. However, because containers are ephemeral by nature, you’ll need the ability to capture either certain files or the entire file system before the container is destroyed. It’s pretty typical for containers to only exist for 30 minutes so the task of getting this data in a timely manner can be nearly impossible without automation.
- Application logs. You may be forwarding application logs from the container to storage or a SIEM. This will come in handy for your investigation if you need context of how the application itself may have been abused.
- Files within the file system. If you can gain access to the file system, yes, you’ll have logs, but you’ll also have access to key files such as malware and forensic artifacts that can be parsed into a log-like format (for example: artifacts from ssh). You will also get operating system logs which are less often forwarded from containers to SIEMs due to performance and cost, but important to identify persistent access and lateral movement.
But the container will only tell part of the story. For example, data acquired from the container itself won’t tell you which credentials were abused for what API calls – only cloud provider logs can give you this level of visibility (which is why it’s so critical to have the right logs enabled). Beyond this, other key data sources when performing cloud forensics include access logs, network data and volatile data.
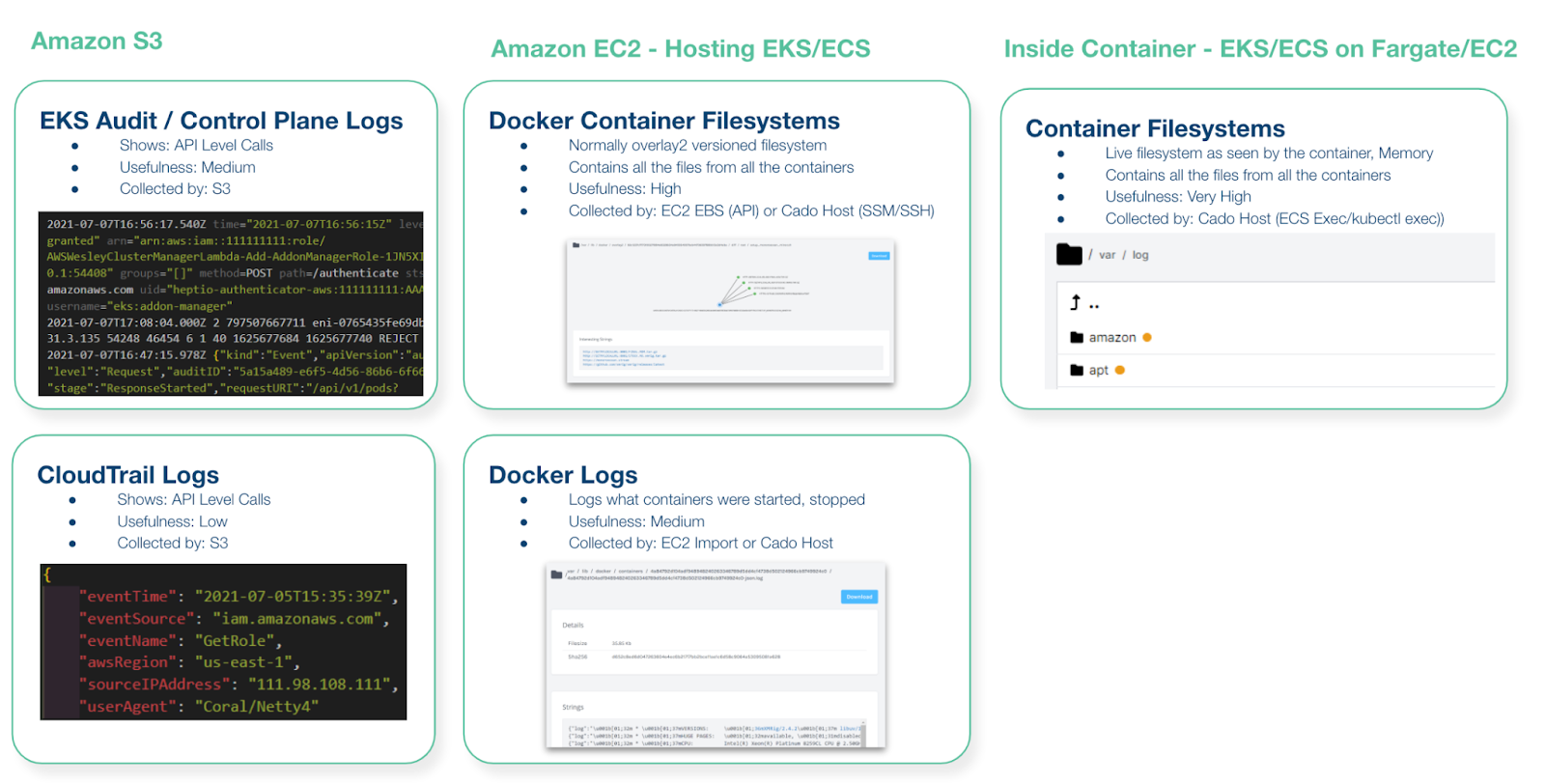
Some Mental Models
One way to think about what data is available where is to consider the trend from On-Premise servers through to Serverless computing:
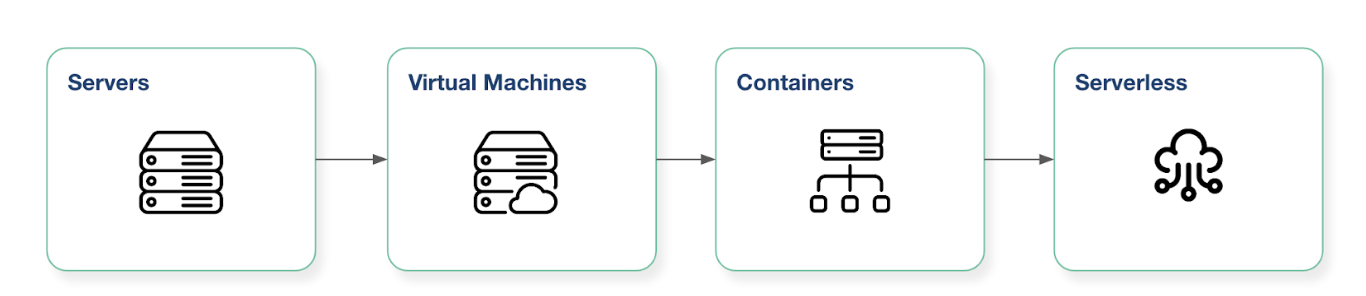
They are all methods of computing that run an operating system in order to execute applications. As such, the forensic evidence they generate is similar. But getting access to more modern computing methods can be difficult as tooling hasn’t caught up yet.
Another way to look at this is the different domains in the cloud. The “AWS Security Incident Response Guide” details the following three “Cloud security incident domains”:

Under this model, logs live across all three domains. And most of the “non-log” data-sources exist in the infrastructure domain.
Finally, we can also split the problem into the classic Control and Data planes:

Where again logs exist across both planes, but you’ll find most of the “non-log” data required for cloud forensics in the Data Plane.
Is On-Premise Forensics just Log Analysis?
A somewhat similar argument could be made for on-premise forensics. A complex ransomware breach involving a Windows network might primarily focus on detailed analysis of logs from domain controllers to identify the scope and patient zero. Or a data-breach investigation might focus on logs from a database to identify what data was stolen and so the impact.
And it could be argued that In a sense everything becomes a log event. We can parse PCAP into flow logs or detections. We can perform a full content scan of files using something like Yara, but the eventual output can be considered a detection log event. But of course we need the full content, not the meta-data, in order to perform that analysis in the first place.
So is Cloud Forensics just Log Analysis? Kind Of. And we’d love to hear your thoughts on the evolving field.
Are you interested in seeing the Cado Cloud Forensics and Incident Response platform in action? Schedule a demo with our team or check out our 14-day free trial.
More from the blog
View All PostsCloud vs. On-Prem Forensics: The Differences You Need to Know
February 11, 2025Continue Reading
Decoding the NIST Cloud Computing Forensics Reference Architecture
July 25, 2023Continue Reading
Revisiting NIST Forensics Guidance in a Cloud Age
December 11, 2023Continue Reading


Subscribe to Our Blog
To stay up to date on the latest from Cado Security, subscribe to our blog today.